Die folgenden Objekte sind maskiert von 'package:semTools':
calculate.D2, cfa.mi, growth.mi, lavaan.mi, lavTestLRT.mi,
lavTestScore.mi, lavTestWald.mi, modificationindices.mi,
modificationIndices.mi, modindices.mi, sem.mi
library(mice)
Attache Paket: 'mice'
Das folgende Objekt ist maskiert 'package:stats':
filter
Die folgenden Objekte sind maskiert von 'package:base':
cbind, rbind
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖readr::clipboard() masks semTools::clipboard()
✖dplyr::filter() masks mice::filter(), stats::filter()
✖dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Exercise A3. For the following exercises, it might be helpful to have the lavaan tutorial page open.
B – Fitting and Evaluating a Model in {lavaan}
Exercise B1. Load the gad7.csv dataset you’ve also used for the EFA-exercises using the code below. It contains responses from over 13’000 participants to multiple scales, including the seven items of the generalized anxiety disorder (GAD-7) scale (e.g., Kroenke et al., 2007), that were collected alongside with other scales by Sauter and Draschkow, 2017 (the complete dataset is openly available at osf.io).
gad7 <-read_csv("01_data/gad7.csv")glimpse(gad7)
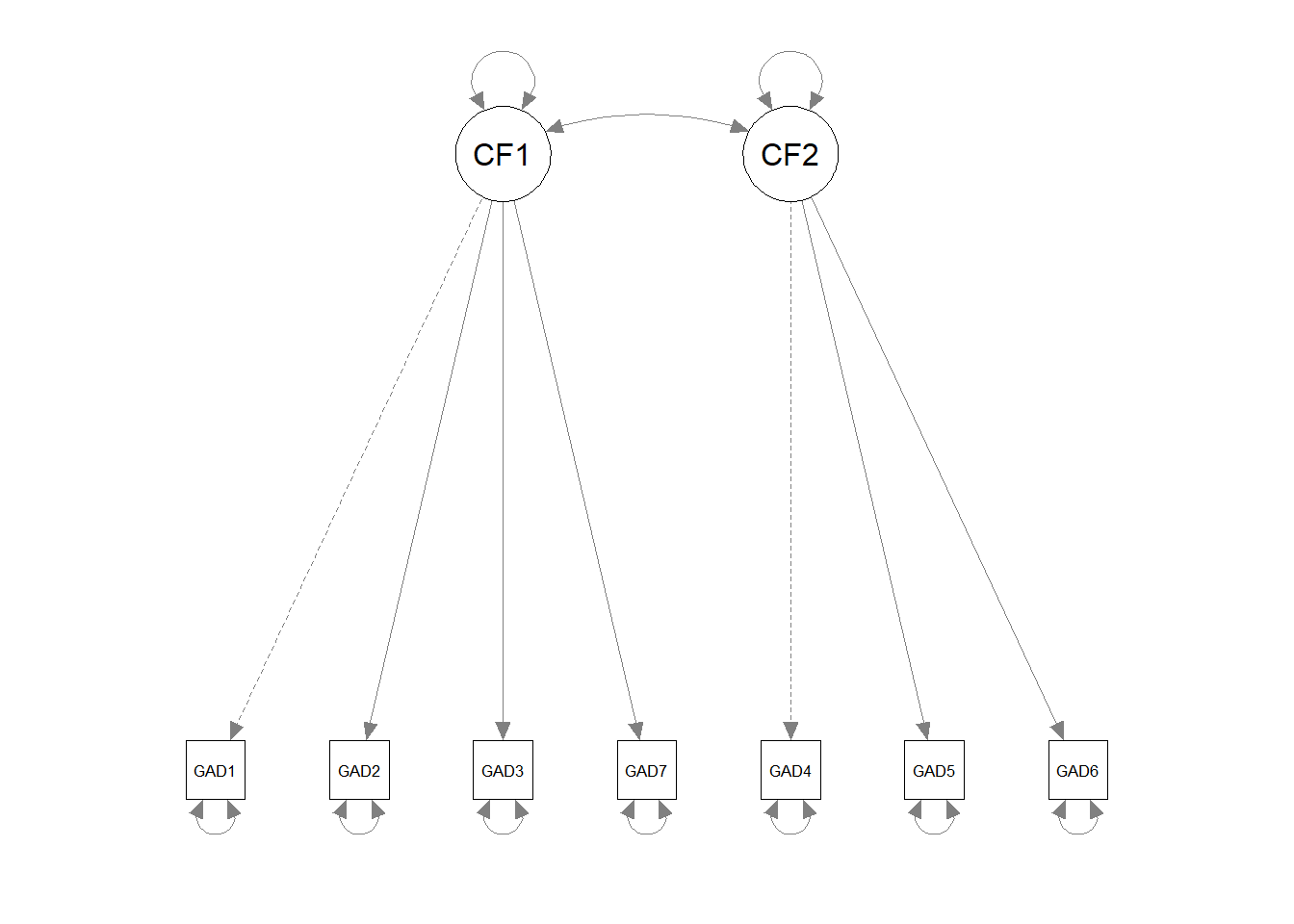
Exercise B2. In the previous exercises on EFA, we used a two-factor solution for the GAD-7 data. Specify a cfa-model in {lavaan} with two factors1. Items GAD1-GAD3 and GAD7 should load on factor 1, items GAD4-GAD6 should load on factor 2. Save the output as gad_2f. Use the lavaan tutorial page as help here.
Exercise B3. In the introduction, you’ve learned that a CFA-model should be evaluated on three levels: global fit, local fit, and interpretability, size, and stat. significance of model parameters. With {lavaan} outputs, you can use the summary() function to get information on model fit. Also, set the argument fit.measures = TRUE to obtain the goodnes of fit indicator. Evaluate the solution from the previous exercise regarding global fit.
Show Solution
summary(gad_2f, fit.measures =TRUE)
lavaan 0.6-19 ended normally after 25 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 15
Number of observations 13464
Model Test User Model:
Test statistic 567.321
Degrees of freedom 13
P-value (Chi-square) 0.000
Model Test Baseline Model:
Test statistic 38698.973
Degrees of freedom 21
P-value 0.000
User Model versus Baseline Model:
Comparative Fit Index (CFI) 0.986
Tucker-Lewis Index (TLI) 0.977
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -106264.271
Loglikelihood unrestricted model (H1) -105980.610
Akaike (AIC) 212558.542
Bayesian (BIC) 212671.158
Sample-size adjusted Bayesian (SABIC) 212623.490
Root Mean Square Error of Approximation:
RMSEA 0.056
90 Percent confidence interval - lower 0.052
90 Percent confidence interval - upper 0.060
P-value H_0: RMSEA <= 0.050 0.004
P-value H_0: RMSEA >= 0.080 0.000
Standardized Root Mean Square Residual:
SRMR 0.023
Parameter Estimates:
Standard errors Standard
Information Expected
Information saturated (h1) model Structured
Latent Variables:
Estimate Std.Err z-value P(>|z|)
CF1 =~
GAD1 1.000
GAD2 1.102 0.011 103.397 0.000
GAD3 1.103 0.011 96.420 0.000
GAD7 0.835 0.011 78.255 0.000
CF2 =~
GAD4 1.000
GAD5 0.598 0.011 53.906 0.000
GAD6 0.663 0.012 53.788 0.000
Covariances:
Estimate Std.Err z-value P(>|z|)
CF1 ~~
CF2 0.445 0.008 57.013 0.000
Variances:
Estimate Std.Err z-value P(>|z|)
.GAD1 0.342 0.005 66.310 0.000
.GAD2 0.212 0.004 51.071 0.000
.GAD3 0.337 0.005 62.401 0.000
.GAD7 0.440 0.006 73.671 0.000
.GAD4 0.315 0.007 42.388 0.000
.GAD5 0.509 0.007 74.400 0.000
.GAD6 0.632 0.008 74.449 0.000
CF1 0.516 0.010 51.276 0.000
CF2 0.535 0.012 46.390 0.000
The \(\chi^2\)-Test is significant, i.e., the model implied covariance matrix and the true covariance matrix differ significantly. However, given the large sample size this is to be expected, even if the model fit is excellent. Therefore, we use fit indices to gauge the model performance: All of them are within the acceptable range and indicate a very good model fit.
Exercise B4. Next, evaluate the local fit of the model. (Hint:lavResiduals() helps you extracting the residual matrix, and modindices() with the argument sort = TRUE returns the modification indices and expected parameter changes).
The differences in the correlation-based residuals (the first matrix cov in the output; here both \(S\) and \(\Sigma\) where transformed to correlation matrices before taking the difference) seem mostly relatively minor (as with the ones we’ve seen in the EFA exercises) and below |.10|, which is what Kline (2023) uses as threshold. The standardized residuals that can be interpreted as z-scores (the second matrix cov.z), include many values lot bigger than the value |2.58| (\(\alpha\)-level of 1%), indicating significant differences. Remember that positive values indicate that the model underestimates the relationships, and negative values indicate that the model overestimates the relationship. However, as with the \(\chi^2\) test, given the huge number of participants we have here, even very small differences are significant. Still, we can see that some relationships, like the ones between GAD3 and GAD7 or between GAD1 and GAD5 are represented much more closely by the model than relationships between, e.g., GAD1 and GAD3, or GAD7 and GAD6.
Again, the huge sample size has a large impact an makes it very hard to interpret, which changes would have meaningful effects (remember that the MIs are \(\chi^2\) values indicating the improvement in model fit if the respective parameter were freely estimated). However, looking at the sepc.all column, we see that some parameters would indeed change substantially, if they were freed. Specifically, allowing a cross-loading for GAD4 would result in a standardized loading above the often-used salience thresholds of .3 or .4. Again, following Brown (2015), we should be able to provide substantive reasons for freeing constrains.
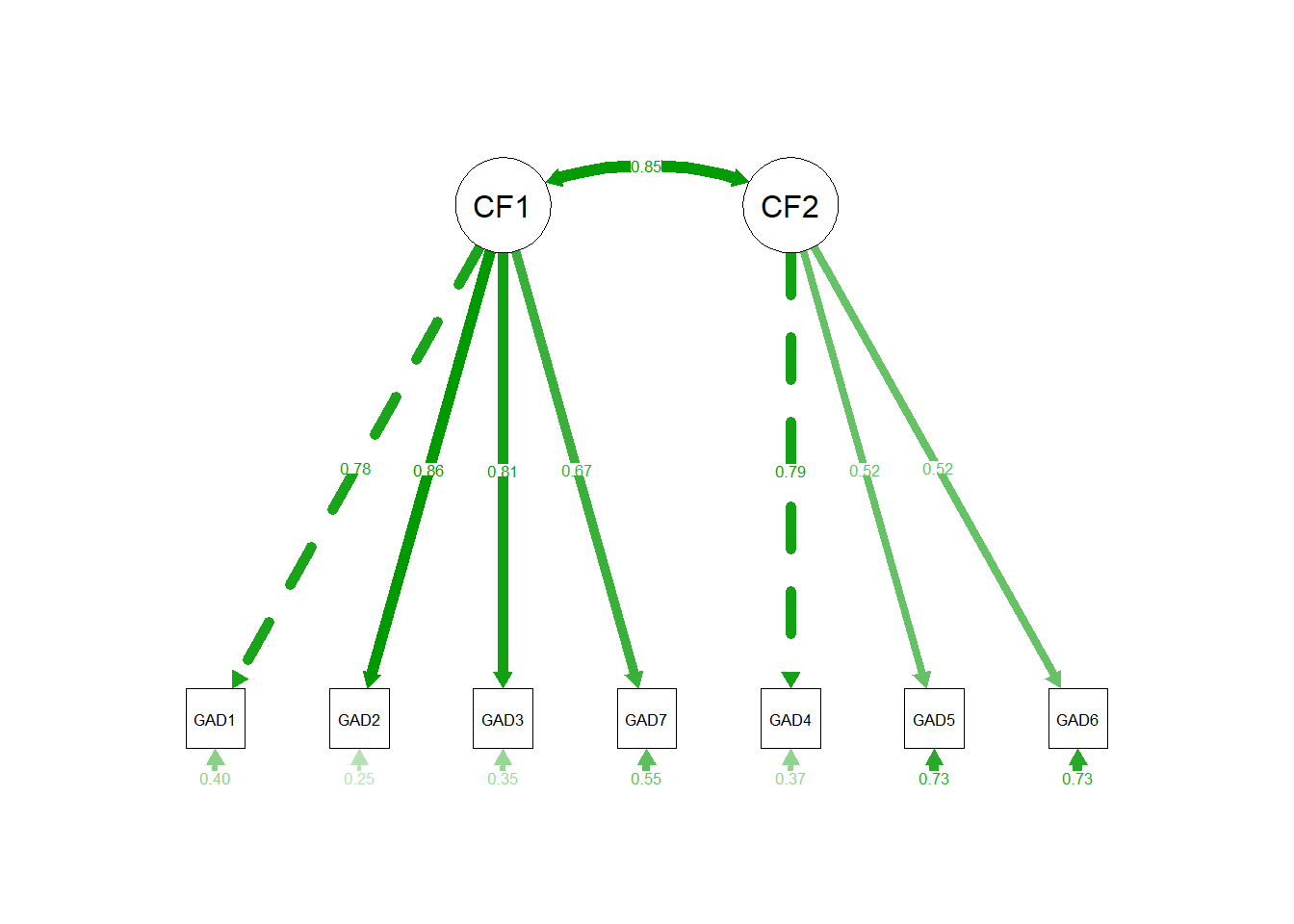
Exercise B5. Finally, evaluate the model parameters. To this end, it makes sense to also look at the fully standardized solution, which you can obtain by adding the argument standardized = TRUE to the summary() function. This will return both a partially standardized solution, in which only the latent variables are standardized (Std.lv in the output) and a completely standardized solution, in which both indicators/MVs and latent variables/CFs are standardized (Std.all in the output).
All loadings are substantial and they are, on average, higher in CF1 than in CF2. They all point in the same direction, which makes sense, given the item formulations. The factor intercorrelation is very high with .85. Standard errors are all relatively small (which makes sense, given the large sample size), but of a similar magnitude, i.e., there are no SEs that are super high or super low relative to the other SEs. No Heywood Cases occurred.
The communalities are not reported in the model, but given that we have no cross-loadings, we can just square the standardized loadings to obtain the communalities, as each indicator loads on only one factor. So the communalities are:
We can see that for GAD5 and GAD6, communalities are rather low.
Exercise B6. Now that you have evaluated the solution regarding global fit, local fit and parameter estimates, how do would you evaluate the model, is it a good model you would work with?
Show Solution
The model appears to be good approximation of the data, however, the low communalities for GAD5 and GAD6, the high modification indices and the EFA results suggest it might make sense to include some cross-loadings or correlated errors (though, again, domain expertise for judging the substantive plausibility for this would be needed: an improvement in model fit can often be achieved either by adding a cross-loading or by correlating the errors of two items from different factors; and which of those, if any, make substantive sense is for the researcher to judge). Alternatively, a one-factor solution (which is also how this scale is used in practice) could be considered. However, again, given the formulation of items GAD5 and GAD6, it makes intuitive sense that their communalities are lower, given that they assess symptoms present in multiple other mental disorders, such as depression or ADHD.
C – Revising the Model
Exercise C1. For the sake of practice, let GAD2 also load on CF2, save it as gad_2f_rev (Remember that the first item is used as reference indicator, so putting GAD2 in first position for estimating the factors is problematic; try it out, if you like…). How does the model change?
The global fit of the model improves slightly, but looking at the local fit, we see an inflation in the SEs of the GAD2 loadings on both factors.
In practice, what you could do from here is fit multiple models, where each has only one constraint freed. Then see whether these affect model fit in the same way and the other model fits disappear, or whether the change in fit is specific to the MIs.
Exercise C2. Now, again for the sake of practice, correlate the errors of GAD4 and GAD6, save it as gad_2f_rev2. Hint: Correlations/covariances are specified using ~~. How did this affect model fit?
Again slight improvements in model fit, though again the substantive interpretation is unclear. You can see how model fit can be improved further and further based on modification indices, rendering the confirmatory approach essentially exploratory. This is why some authors also prefer the terms restricted and unrestricted factor analysis rather than CFA and EFA.
Exercise C3. Now, also fit a one-factor model, where all items load on the same factor, save it as gad_1f. This is how the GAD-7 Score is usually interpreted: As a unidimensional score. Evaluate the model.
The correlation-based residuals are quite a bit larger than in the two-factor solution, with the ones for GAD4 ~~ GAD5 and GAD5 ~~ GAD6 being a bit large according to Kline (2023). Most of the standardized residuals are substantially above the 2.58 (\(\alpha\)-level of 1%). But again, this is not surprising given the large N.
Communalities look comparable to the ones from the two-factor model.
Overall evaluation:
Although the model looks acceptable according to global fit measuers, items 5 and 6 don’t really fit in the view of a unidimensional construct.
D – Model Comparison
Exercise D1. You have now fitted four different models: gad_1f, gad_2f, gad_2f_rev, gad_2f_rev2. Compare them using likelihood-ratio tests (\(\chi^2\)-difference tests) with the anova() function. Which model performs best according to these tests and also according to AIC and BIC?
The model with the two freed parameters clearly performs the best across all global-fit indicators. But again, model specification should be judged not solely on global fit.
E – Visualizing the Model (optional)
Exercise E1. There exist mutliple packages to visualize your CFA/SEM model from a {lavaan} output, e.g. lavaanPlot::lavaanPlot, see here, and semPlot::semPaths(), see here. Create a visualization of one or multiple of the factor models, just to get a feeling for how this might look.
# add parameterslavaanPlot(gad_2f, coefs =TRUE, stand =TRUE, covs =TRUE)
F – Ordinal Data
Exercise F1. So far, we have used maximum likelihood estimation. As the items were assessed on a four-point Likert scale, it makes sense to treat the responses as ordinal. To account for this, refit the two-factor model, but with out the freed parameters, and set the argument ordered = TRUE in the cfa() function. This will automatically adjust the estimator. Save the output as gad_2f_ord.
The global fit is very good, however, note that the standard fit indices are likely not interpretable by the same standards as when ML-estimation was used. (e.g., Savalei, 2021; Shi & Maydeu-Olivares, 2020; Xia & Yang, 2019). Therefore you should look at the Scaled statistics in the output. These still point towards an acceptable to good global fit.
The correlation-based residuals are all clearly below .1. The standardized residuals (z-values) are still relatively large. Note that the output contains more information, as the model now also estimated thresholds assumend to be used for the discretization.
Communalities are larger than when ML-estimation is used. Communalities of items GAD5 and GAD6 now come closer to the conventional threshold of .4.
Overall evaluation:
Both global and local model fit are better than when ML-estimation is used.
G – Handling Missing Values
Exercise G1. So far, we have used {lavaan}s default handling of missing values, which is list-wise deletion. Refit the model using full information maximum likelihood (FIML) / direct ML estimation to impute missing values by adding the argument missing = "ml" (aliases are "fiml" or "direct", so you might come across these in other {lavaan} syntax). Look at the solution.
lavaan 0.6-19 ended normally after 25 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 22
Number of observations 13464
Number of missing patterns 1
Model Test User Model:
Test statistic 567.321
Degrees of freedom 13
P-value (Chi-square) 0.000
Model Test Baseline Model:
Test statistic 38698.973
Degrees of freedom 21
P-value 0.000
User Model versus Baseline Model:
Comparative Fit Index (CFI) 0.986
Tucker-Lewis Index (TLI) 0.977
Robust Comparative Fit Index (CFI) 0.986
Robust Tucker-Lewis Index (TLI) 0.977
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -106264.271
Loglikelihood unrestricted model (H1) -105980.610
Akaike (AIC) 212572.542
Bayesian (BIC) 212737.713
Sample-size adjusted Bayesian (SABIC) 212667.799
Root Mean Square Error of Approximation:
RMSEA 0.056
90 Percent confidence interval - lower 0.052
90 Percent confidence interval - upper 0.060
P-value H_0: RMSEA <= 0.050 0.004
P-value H_0: RMSEA >= 0.080 0.000
Robust RMSEA 0.056
90 Percent confidence interval - lower 0.052
90 Percent confidence interval - upper 0.060
P-value H_0: Robust RMSEA <= 0.050 0.004
P-value H_0: Robust RMSEA >= 0.080 0.000
Standardized Root Mean Square Residual:
SRMR 0.021
Parameter Estimates:
Standard errors Standard
Information Observed
Observed information based on Hessian
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
CF1 =~
GAD1 1.000 0.718 0.775
GAD2 1.102 0.011 103.903 0.000 0.792 0.865
GAD3 1.103 0.012 95.430 0.000 0.793 0.807
GAD7 0.835 0.011 77.964 0.000 0.600 0.671
CF2 =~
GAD4 1.000 0.731 0.793
GAD5 0.598 0.011 54.613 0.000 0.437 0.522
GAD6 0.663 0.013 52.640 0.000 0.485 0.521
Covariances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
CF1 ~~
CF2 0.445 0.008 56.646 0.000 0.848 0.848
Intercepts:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.GAD1 0.861 0.008 107.826 0.000 0.861 0.929
.GAD2 0.673 0.008 85.326 0.000 0.673 0.735
.GAD3 0.966 0.008 114.030 0.000 0.966 0.983
.GAD7 0.589 0.008 76.384 0.000 0.589 0.658
.GAD4 0.724 0.008 91.132 0.000 0.724 0.785
.GAD5 0.488 0.007 67.659 0.000 0.488 0.583
.GAD6 0.911 0.008 113.528 0.000 0.911 0.978
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.GAD1 0.342 0.005 66.237 0.000 0.342 0.399
.GAD2 0.212 0.004 51.113 0.000 0.212 0.252
.GAD3 0.337 0.005 62.632 0.000 0.337 0.349
.GAD7 0.440 0.006 73.536 0.000 0.440 0.550
.GAD4 0.315 0.007 43.053 0.000 0.315 0.370
.GAD5 0.509 0.007 74.152 0.000 0.509 0.727
.GAD6 0.632 0.009 74.192 0.000 0.632 0.728
CF1 0.516 0.010 51.261 0.000 1.000 1.000
CF2 0.535 0.011 46.688 0.000 1.000 1.000
Exercise G2. When we use the DWLS-estimator, no direct imputation method is available. So here we can use multiple imputation. The {lavaan.mi}-package provides helpful functions to do this. They are named just like their {lavaan}-counterpart, but with a .mi suffix. Refit the model from Exercise F1 but use the cfa.mi() function. Look at the results.
lavaan.mi object fit to 5 imputed data sets using:
- lavaan (0.6-19)
- lavaan.mi (0.1-0)
See class?lavaan.mi help page for available methods.
Convergence information:
The model converged on 5 imputed data sets.
Standard errors were available for all imputations.
Estimator DWLS
Optimization method NLMINB
Number of model parameters 29
Number of observations 13464
Model Test User Model:
Standard Scaled
Test statistic 239.844 532.259
Degrees of freedom 13 13
P-value 0.000 0.000
Average scaling correction factor 0.451
Average shift parameter 0.616
simple second-order correction
Pooling method D2
Pooled statistic "standard"
"scaled.shifted" correction applied AFTER pooling
Model Test Baseline Model:
Test statistic 165963.072 95916.802
Degrees of freedom 21 21
P-value 0.000 0.000
Scaling correction factor 1.730
User Model versus Baseline Model:
Comparative Fit Index (CFI) 0.999 0.995
Tucker-Lewis Index (TLI) 0.998 0.991
Robust Comparative Fit Index (CFI) 0.981
Robust Tucker-Lewis Index (TLI) 0.969
Root Mean Square Error of Approximation:
RMSEA 0.036 0.054
90 Percent confidence interval - lower 0.032 0.051
90 Percent confidence interval - upper 0.040 0.058
P-value H_0: RMSEA <= 0.050 1.000 0.030
P-value H_0: RMSEA >= 0.080 0.000 0.000
Robust RMSEA 0.077
90 Percent confidence interval - lower 0.071
90 Percent confidence interval - upper 0.083
P-value H_0: Robust RMSEA <= 0.050 0.000
P-value H_0: Robust RMSEA >= 0.080 0.213
Standardized Root Mean Square Residual:
SRMR 0.025 0.025
Parameter Estimates:
Parameterization Delta
Standard errors Robust.sem
Information Expected
Information saturated (h1) model Unstructured
Pooled across imputations Rubin's (1987) rules
Augment within-imputation variance Scale by average RIV
Wald test for pooled parameters t(df) distribution
Pooled t statistics with df >= 1000 are displayed with
df = Inf(inity) to save space. Although the t distribution
with large df closely approximates a standard normal
distribution, exact df for reporting these t tests can be
obtained from parameterEstimates.mi()
Latent Variables:
Estimate Std.Err t-value df P(>|t|) Std.lv
CF1 =~
GAD1 1.000 0.825
GAD2 1.123 0.006 177.510 Inf 0.000 0.926
GAD3 1.038 0.006 179.478 Inf 0.000 0.856
GAD7 0.913 0.007 123.662 Inf 0.000 0.753
CF2 =~
GAD4 1.000 0.853
GAD5 0.701 0.011 62.201 Inf 0.000 0.598
GAD6 0.678 0.010 67.327 Inf 0.000 0.579
Std.all
0.825
0.926
0.856
0.753
0.853
0.598
0.579
Covariances:
Estimate Std.Err t-value df P(>|t|) Std.lv
CF1 ~~
CF2 0.605 0.006 102.278 Inf 0.000 0.860
Std.all
0.860
Thresholds:
Estimate Std.Err t-value df P(>|t|) Std.lv
GAD1|t1 -0.194 0.011 -17.880 Inf 0.000 -0.194
GAD1|t2 0.847 0.012 68.692 Inf 0.000 0.847
GAD1|t3 1.369 0.015 88.787 Inf 0.000 1.369
GAD2|t1 0.165 0.011 15.230 Inf 0.000 0.165
GAD2|t2 0.959 0.013 74.837 Inf 0.000 0.959
GAD2|t3 1.474 0.016 90.095 Inf 0.000 1.474
GAD3|t1 -0.266 0.011 -24.326 Inf 0.000 -0.266
GAD3|t2 0.658 0.012 56.258 Inf 0.000 0.658
GAD3|t3 1.251 0.015 86.197 Inf 0.000 1.251
GAD7|t1 0.324 0.011 29.456 Inf 0.000 0.324
GAD7|t2 1.024 0.013 77.962 Inf 0.000 1.024
GAD7|t3 1.530 0.017 90.425 Inf 0.000 1.530
GAD4|t1 0.074 0.011 6.842 Inf 0.000 0.074
GAD4|t2 0.908 0.013 72.120 Inf 0.000 0.908
GAD4|t3 1.465 0.016 90.016 Inf 0.000 1.465
GAD5|t1 0.484 0.011 42.969 Inf 0.000 0.484
GAD5|t2 1.162 0.014 83.473 Inf 0.000 1.162
GAD5|t3 1.632 0.018 90.377 Inf 0.000 1.632
GAD6|t1 -0.253 0.011 -23.175 Inf 0.000 -0.253
GAD6|t2 0.742 0.012 62.048 Inf 0.000 0.742
GAD6|t3 1.392 0.016 89.155 Inf 0.000 1.392
Std.all
-0.194
0.847
1.369
0.165
0.959
1.474
-0.266
0.658
1.251
0.324
1.024
1.530
0.074
0.908
1.465
0.484
1.162
1.632
-0.253
0.742
1.392
Variances:
Estimate Std.Err t-value df P(>|t|) Std.lv
.GAD1 0.320 0.320
.GAD2 0.143 0.143
.GAD3 0.268 0.268
.GAD7 0.433 0.433
.GAD4 0.272 0.272
.GAD5 0.642 0.642
.GAD6 0.665 0.665
CF1 0.680 0.007 102.668 Inf 0.000 1.000
CF2 0.728 0.010 72.363 Inf 0.000 1.000
Std.all
0.320
0.143
0.268
0.433
0.272
0.642
0.665
1.000
1.000
H – Measurement Invariance
Exercise H1. An important question is whether a measurement model is invariant across groups, i.e., whether the same model structure and parameters apply to all groups (e.g. across genders). When would a non-invariance occur? For example, if women would tend to agree to some items more than men, not because they have higher values in their true latent anxiety score, but because it is socially more acceptable/less stigmatized behavior in women than in men. Test the configural, weak, strong, and strict factorial invariance across genders for the gad_2f_fiml model, using the group.equal argument of cfa() (see also lavaan group comparison tutorial). Compare the models using an LRT (lavTestLRT()).
Show Solution
model <-' CF1 =~ GAD1 + GAD2 + GAD3 + GAD7 CF2 =~ GAD4 + GAD5 + GAD6'# configural invariancegad7_2f_conf <-cfa(model, data = gad7, missing ="ml", group ="Gender")# weak invariancegad7_2f_weak <-cfa(model, data = gad7, missing ="ml", group ="Gender",group.equal ="loadings")# strong invariancegad7_2f_strong <-cfa(model, data = gad7, missing ="ml", group ="Gender",group.equal =c("intercepts", "loadings"))# strict invariancegad7_2f_strict <-cfa(model, data = gad7, missing ="ml", group ="Gender",group.equal =c("residuals", "intercepts", "loadings"))# model comparison testslavTestLRT(gad7_2f_conf, gad7_2f_weak, gad7_2f_strong, gad7_2f_strict)
The LRT sequentially compares the models to each other. According to these tests, no invariance is supported. But given the high sample-size this is again unsurprising. In such a situation, we can also look at differences in fit indeces (see Chen, 2007 for details). Remeber, cut-offs for \(\Delta\) fit indices, according to Chen (2007) are:
Loadings invariant if: \(\Delta CFI \leq -.005\) and \(\Delta RMSEA \geq .010\) or \(\Delta SRMR \geq .025\)
Intercept or residuals invariant if: \(\Delta CFI \leq -.005\) and \(\Delta RMSEA \geq .010\) or \(\Delta SRMR \geq .005\)
The parameter estimates do look quite different across models. Note the low N for Gender == "other", thus this solution is likely unstable.
I – Higher-Order Models
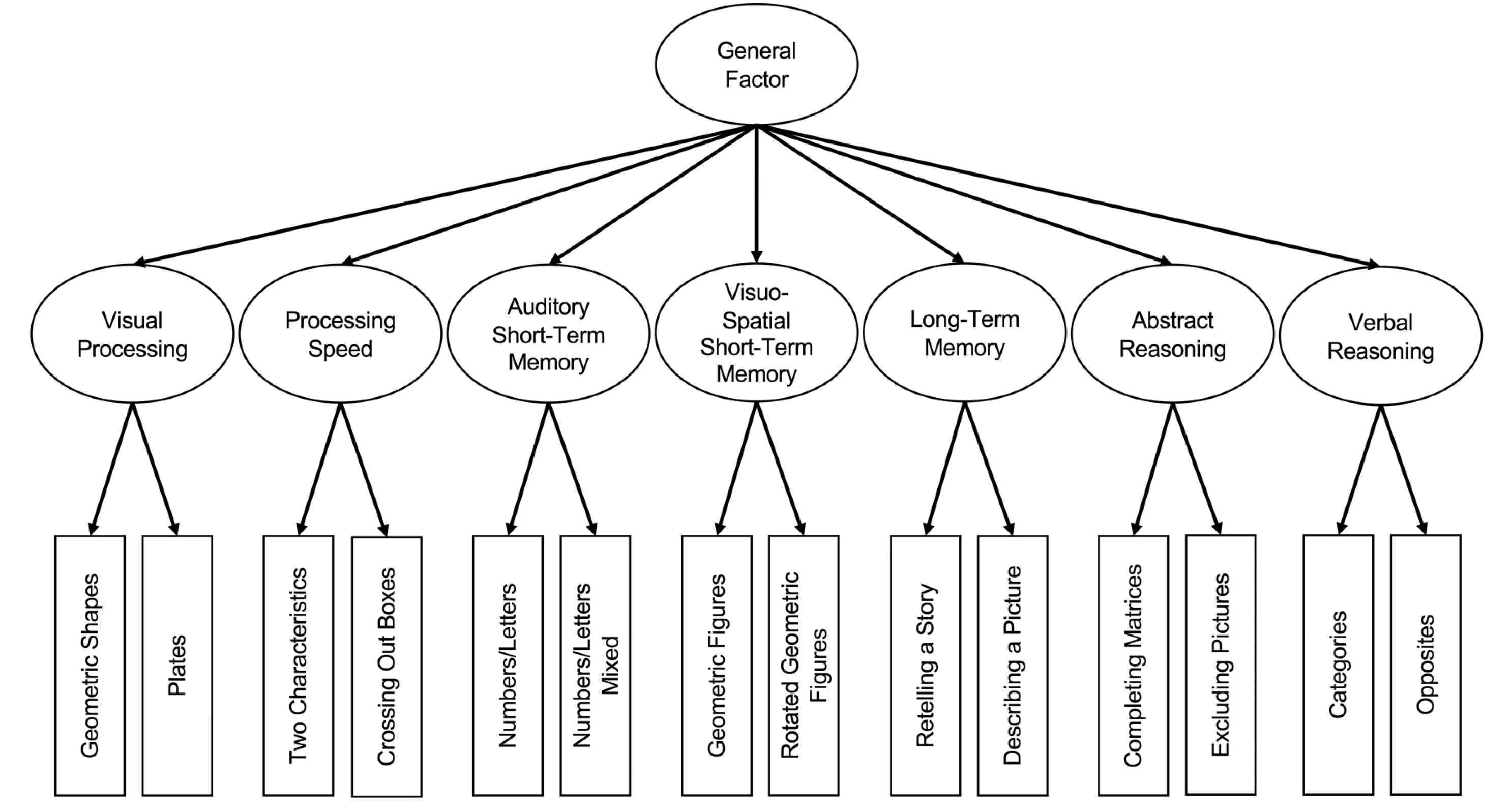
Sometimes, we have multiple latent factors and want to model their covariances with a higher-order factor. Probably the most prominent example is intelligence tests, where we have multiple subtests per group factor and then a general factor on top. While we have no raw-data available, but given a correlation matrix and SDs, we can compute the covariance matrix and run the CFA with this. This means that if you see a paper and want to replicate the analyses, you can do so given the correlation matrix, SD vector, and sample size (and mean vector, if the mean structure is needed). The EFAtools package contains the IDS2_R data, which is the correlation matrix among subtests of the intelligence and development scales - 2 used in Grieder & Grob (2020). This matrix is based on the standardihzation and validation sample of N = 1991 children and adolescents aged 5 to 20 years. They also report the SDs in their paper, copy the code below to get the correlation matrix and SDs:
Exercise I1. Compute the covariance matrix IDS2_S from the information above, once using the {lavaan}cor2cov() function and once by hand: \(DRD\), where \(D\) is the diagonal matrix of the SDs and \(R\) is the correlation matrix. Do the two matrices match?
Exercise I2. Below is a picture of the theoretical model of the IDS2 (Figure by Grieder & Grob, 2020). Use this picture and the subscale names in IDS2_S (see also ?EFAtools::IDS2_R for the full names) to build and fit a CFA first with only a first-order structure in {lavaan}, i.e., do not yet include a higher order factor (feel free to abbreviate the names of the group factors). To this end, specify the sample.cov and sample.nobs arguments in cfa() with the covariance matrix and the sample size. How does the model fit?
The standardized residuals vary substantially. Some are very low and some are clearly above 2.58. However, the differences between the correlations are all clearly below |.1|.
Some MIs are relatively large, matching the conclusion by Grieder & Grob (2020), that not all factors of the theorized structure could be separated empirically.
Exercise I3. Now, refit the model, but add a higher-order factor. To do so, you can use the same {lavaan} syntax you’ve used so far, but on the right hand side of =~, you list the names of the group factors. Does the fit change much?
According to the LRT, the higher-order model fits significantly worse overall.
J – Your turn
Exercise J1. Do you have own data with scales you want to validate the structure? Try it out using {lavaan}.
References
Brown, T. A. (2015). Confirmatory Factor Analysis for Applied Research (2nd ed.). The Guilford Press.
Chen, F. F. (2007). Sensitivity of Goodness of Fit Indexes to Lack of Measurement Invariance. Structural Equation Modeling: A Multidisciplinary Journal, 14(3), 464–504. https://doi.org/10.1080/10705510701301834
Grieder, S., & Grob, A. (2020). Exploratory Factor Analyses of the Intelligence and Development Scales–2: Implications for Theory and Practice. Assessment, 27(8), 1853–1869. https://doi.org/10.1177/1073191119845051
Kline, R. B. (2023). Principles and practice of structural equation modeling (5th ed.). The Guilford Press.
Kroenke, K., Spitzer, R. L., Williams, J. B. W., Monahan, P. O., & Löwe, B. (2007). Anxiety Disorders in Primary Care: Prevalence, Impairment, Comorbidity, and Detection. Annals of Internal Medicine, 146(5), 317–325. https://doi.org/10.7326/0003-4819-146-5-200703060-00004
Nájera, P., Abad, F. J., & Sorrel, M. A. (2025). Is exploratory factor analysis always to be preferred? A systematic comparison of factor analytic techniques throughout the confirmatory–exploratory continuum. Psychological Methods, 30(1), 16–39. https://doi.org/10.1037/met0000579
Savalei, V. (2021). Improving Fit Indices in Structural Equation Modeling with Categorical Data. Multivariate Behavioral Research, 56(3), 390–407. https://doi.org/10.1080/00273171.2020.1717922
Shi, D., & Maydeu-Olivares, A. (2020). The Effect of Estimation Methods on SEM Fit Indices. Educational and Psychological Measurement, 80(3), 421–445. https://doi.org/10.1177/0013164419885164
Xia, Y., & Yang, Y. (2019). RMSEA, CFI, and TLI in structural equation modeling with ordered categorical data: The story they tell depends on the estimation methods. Behavior Research Methods, 51(1), 409–428. https://doi.org/10.3758/s13428-018-1055-2
Footnotes
Note that usually it is not recommended to perform a CFA on the same data the EFA has been performed on. However, see Nájera et al. (2025) for an approach that explicitly uses this combination↩︎